The problem with Agents writing your pull requests
The hidden coordination problem behind AI-generated pull requests.

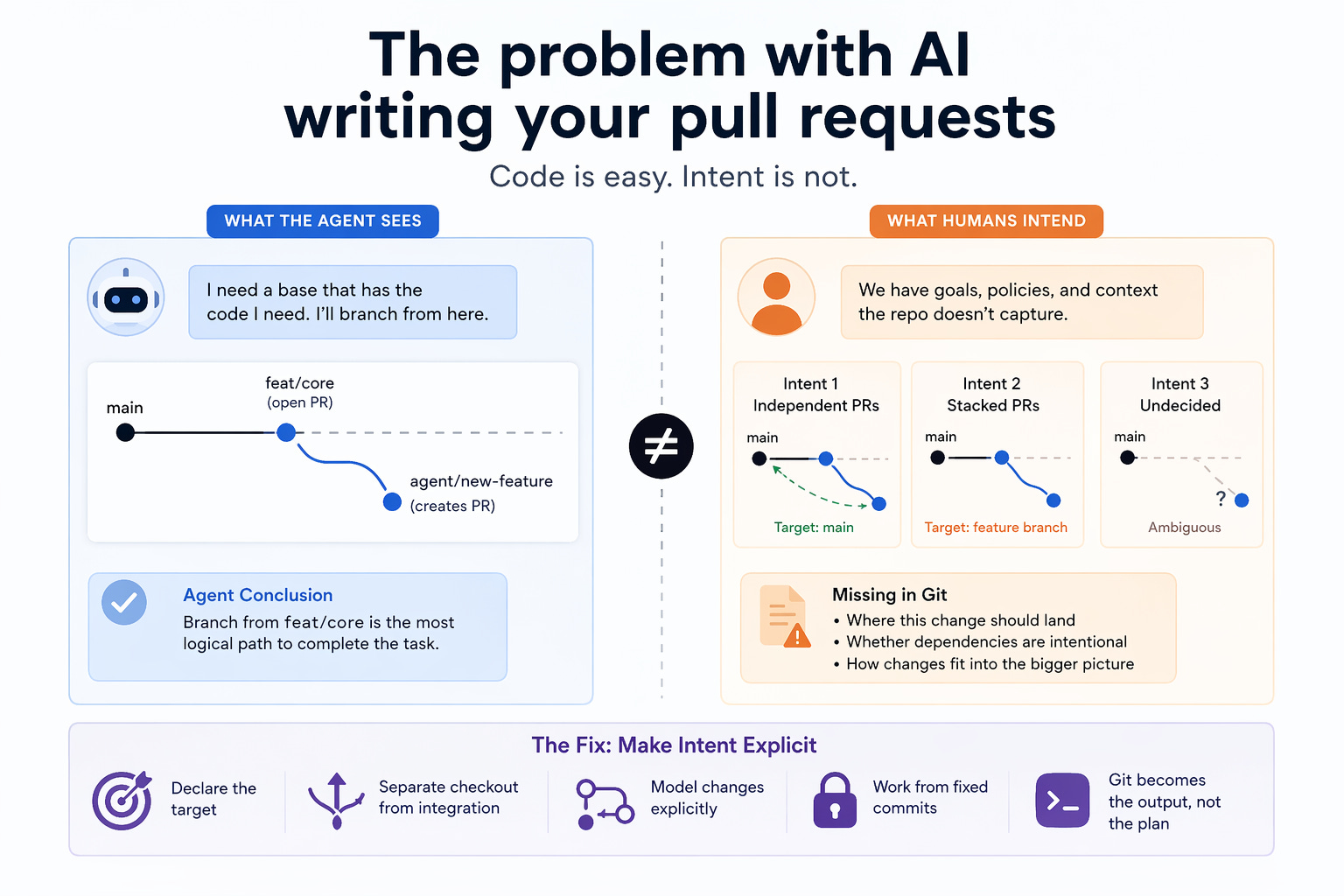
Something odd shows up once you let agents loose in a repo for long enough. The code is usually fine—sometimes better than what people would write under pressure—but the pull requests get strange. You’ll see one open and it’s targeting a feature branch instead of main, and now you’ve got a stacked PR nobody asked for and a reviewer trying to reverse engineer what the agent was thinking. It looks like a mistake, but it isn’t. It’s the only move that made sense given what the agent could see.
Git doesn’t actually carry intent. A branch is just a pointer to a commit. That’s the entire model. Everything else we attach to it—this branch is independent, this one depends on another PR, this one is safe to merge—lives outside the system. It’s in people’s heads, or scattered across Slack, PR descriptions, and whatever conventions the team has built up over time. Humans fill in those gaps without noticing. Agents don’t. They only see the structure that’s actually there.
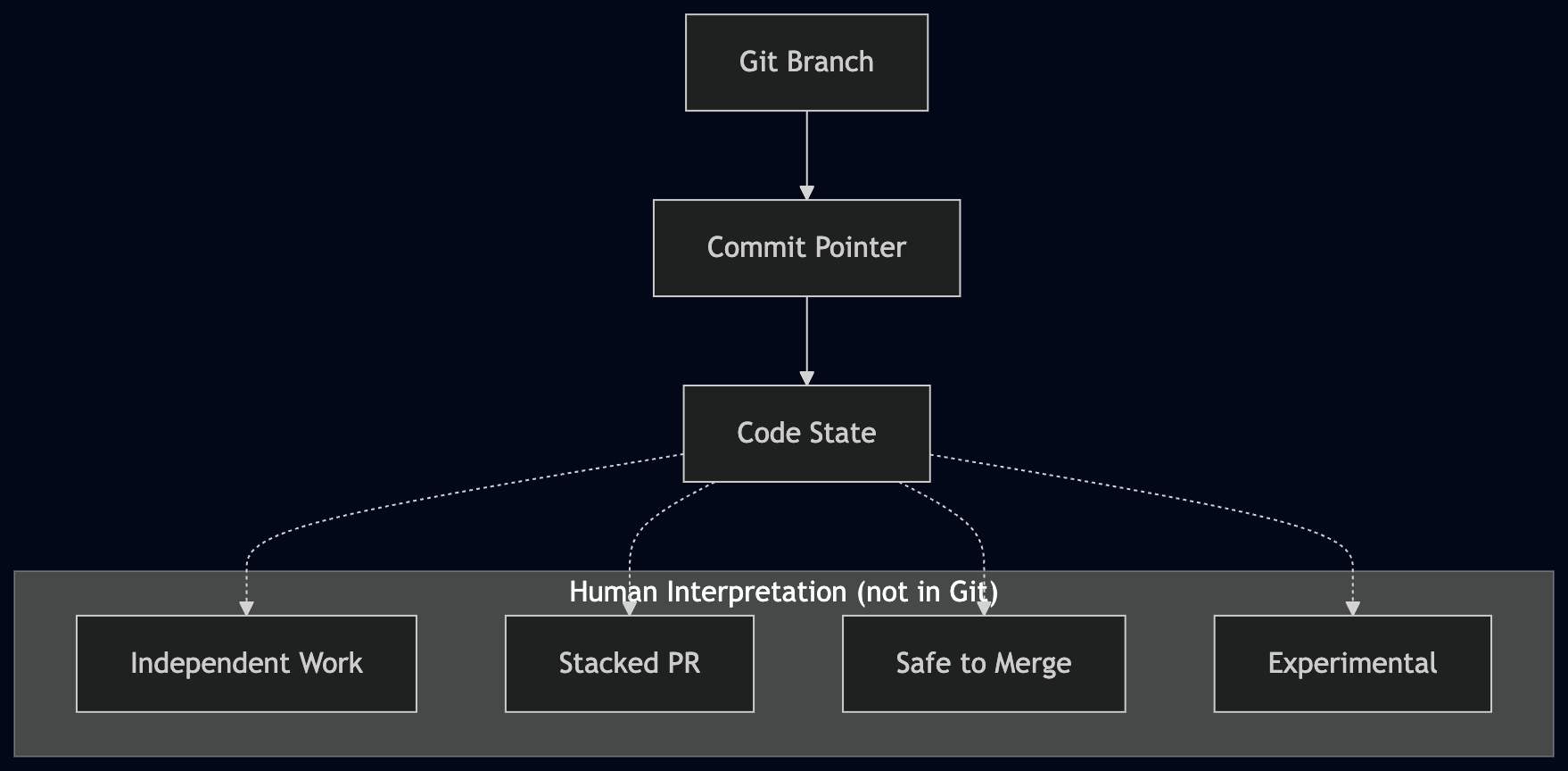
The break happens in a very ordinary scenario. main is missing some core functionality. There’s an open PR that adds it. Now you ask the agent to build something that depends on that code. From its perspective, the clean move is to branch from the PR that already contains what it needs. That’s not a failure. That’s coherence. But from a human perspective, it might be completely wrong. Maybe you expected two clean PRs into main. Maybe you wanted stacking. Maybe you hadn’t decided. The repository never said, so the agent guessed. That’s the branch inference problem.

From the agent’s view, this is logical. It followed the path where the required code exists.
From the human view, there were multiple valid intentions:
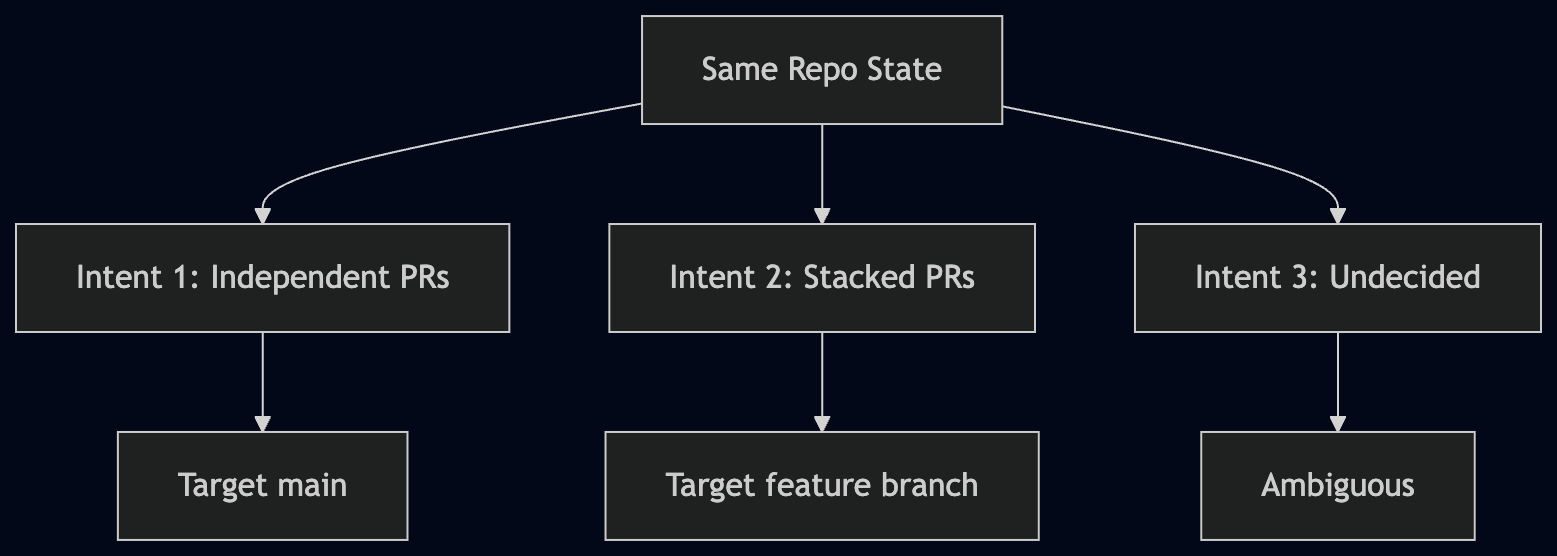
The system never told the agent which of these was correct.
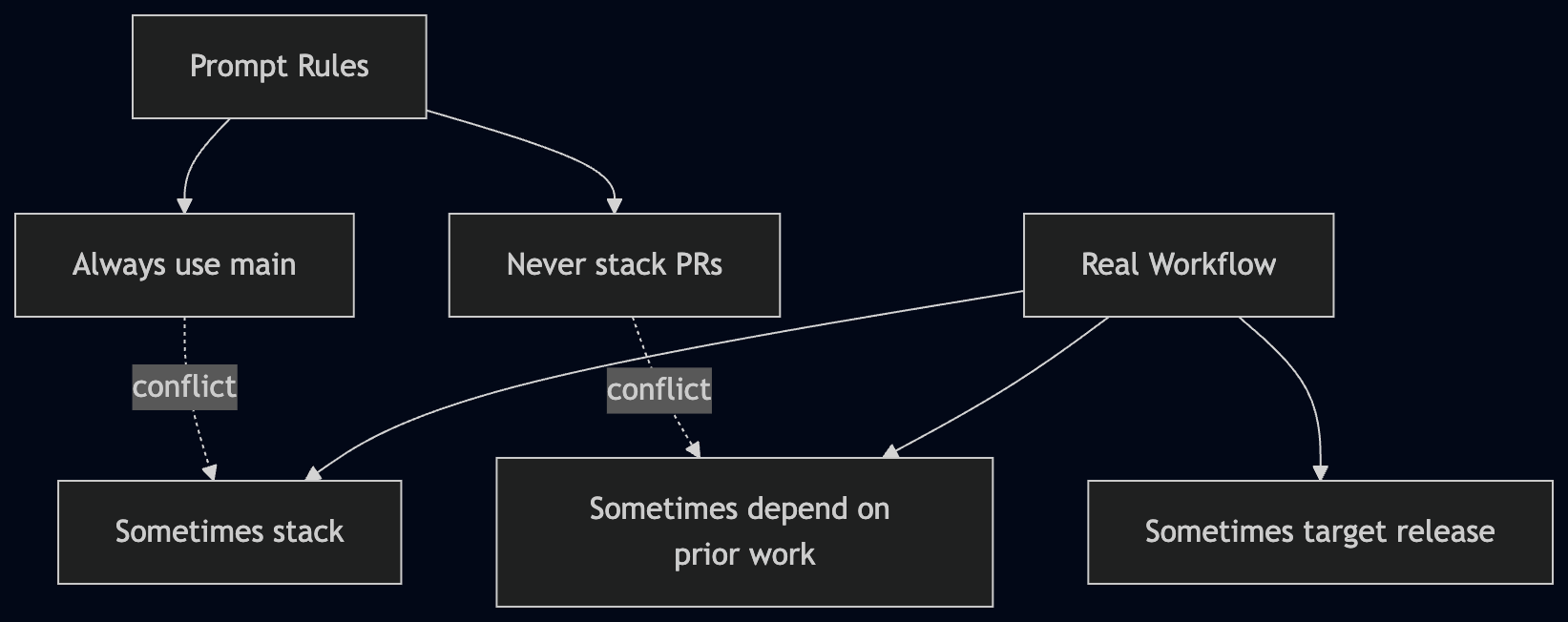
People usually try to fix this with prompts. “Always branch from main.” “Don’t stack PRs.” That works until it doesn’t, because real workflows aren’t that clean. Sometimes stacking is exactly what you want. Hotfixes go to release branches. Feature work builds on other feature work. Sometimes the second change really does depend on the first. At that point the rules start fighting the workflow, and the agent is stuck choosing between conflicting instructions. The issue isn’t that the agent needs better guidance. It’s that the system never told it what the target was.
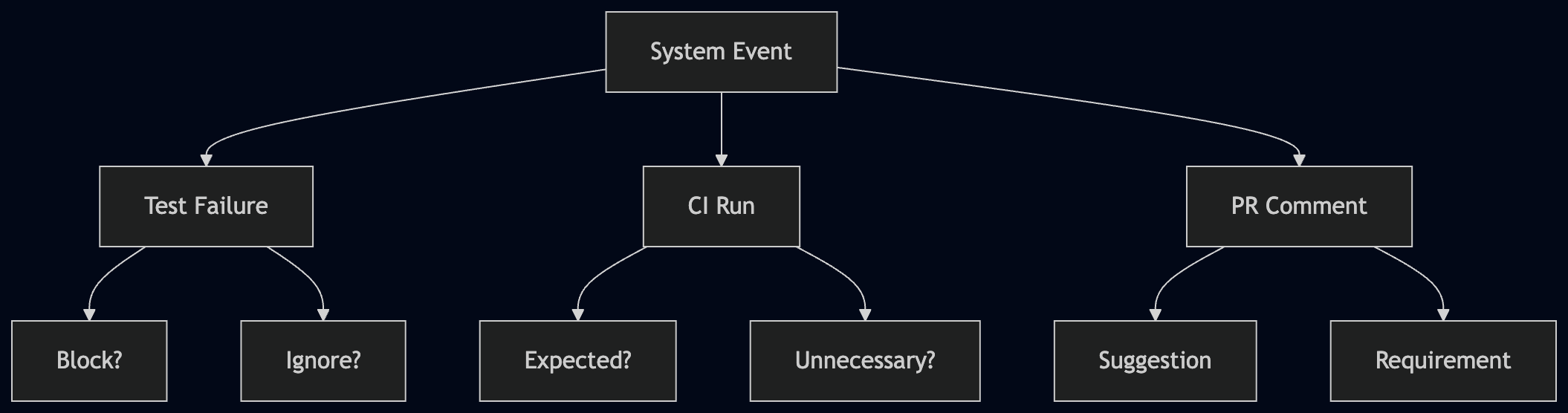
Once you see it, the pattern shows up everywhere. A test fails—should that block the PR or is it expected? A CI job runs—should it have? Someone leaves a comment—are they asking for a change or just thinking out loud? Humans read between the lines because we share context. Agents don’t have that context, so they default to inference. Sometimes that inference is reasonable and still wrong.
What actually helps is simpler than people expect. You don’t need a smarter agent. You need a clearer system. Start by making the integration target explicit. Every agent run should know where its work is supposed to land before it writes anything back. If the PR is meant for main, that should be stated. If it’s part of a stack, that should be stated too. Once that’s visible, the behavior stops being surprising.
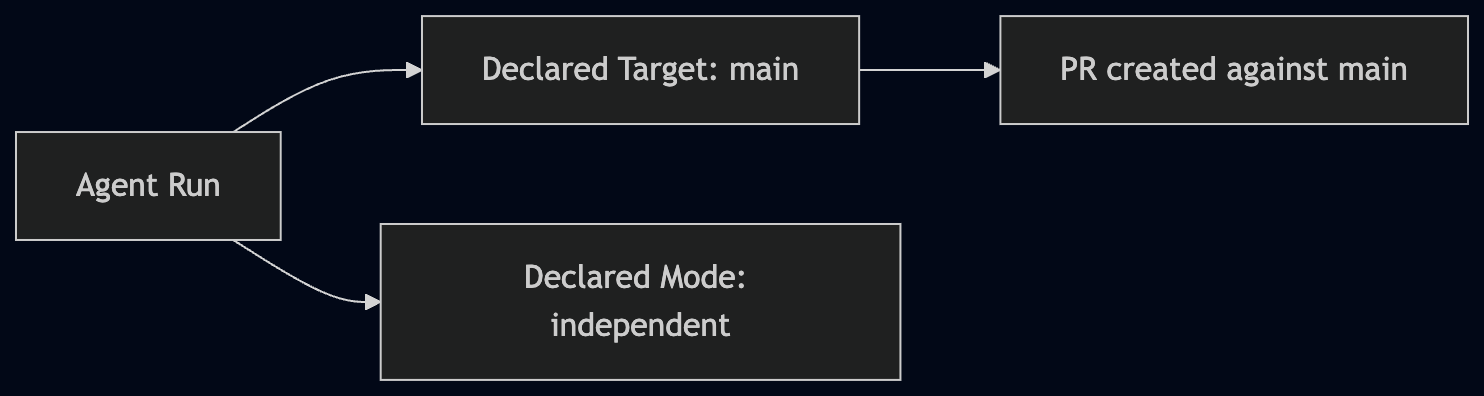
There’s also a subtle distinction that causes a lot of unnecessary problems. Where the agent starts from and where the PR lands are not the same decision. An agent might need to read from a feature branch to do the work, but still open a PR against main. We tend to collapse those into one thing, and that forces bad tradeoffs. Separating them makes the system behave much more predictably.

If you take it a step further, the real fix is to stop using branches as the thing that carries intent at all. Branches are fine for moving code around, but they’re a weak way to represent relationships between changes. What you actually want is something explicit: a fixed starting point (a commit, not a moving branch), declared dependencies, and a clear integration target. At that point Git becomes the output, not the thing the agent is reasoning over.
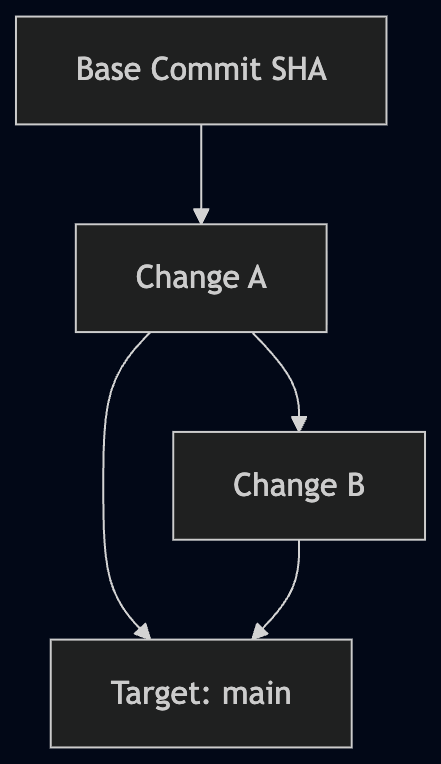
There’s one more detail that matters more than it seems. Branches move. If an agent is working and the base branch updates underneath it, you’ve just changed its ground truth mid-task. That’s where subtle bugs creep in. Working from a pinned commit avoids that entirely. Rebasing becomes a deliberate step instead of something that happens implicitly.
None of this means Git is the problem. You still want PRs, CI, history, and all the tooling around it. But Git alone isn’t enough once agents are making decisions inside your workflow. It was built for humans who can interpret intent, not for systems that need that intent spelled out.
This isn’t a niche edge case. It’s what happens when you take infrastructure designed around human judgment and hand it to something that doesn’t guess the same way you do. Humans can work around missing context. Agents can’t. If the system doesn’t say what it means, the agent will make something up. And eventually, that guess will be wrong.